Building a LibreWolf Browser Setup with reasonable privacy and Vim Keybindings
The web browser is one of the most important programs in my day-to-day work on the computer. I want a browser setup that addresses a couple of goals. First I’d like to be independent of large corporations that try to observe my browsing behaviour for their profit. That is why I’d rather use an open source implementation instead of the various chrome based browsers. Since the servo browser1 is not there yet2, a mozilla firefox based browser is the most viable option as of today. Because Mozilla has started to put more and more questionable features into the firefox main release line, I was looking to try one of the open source forks promising more privacy. I need a reasonable tradeoff between privacy and ease of use. That is why I didn’t went with the tor browser providing the best privacy of the alternatives I looked at. I settled with the LibreWolf browser.
The tiling window manager on my linux distribution can be completely managed from the keyboard without having to use the mouse. That is why I’d like to have improved keybindings for my browser as well. Since I’m using vim bindings for many of my other programs as well a vi plugin serves me very well in this regard. I added the firefox extension Tridactyl to LibreWolf.
Finally I also wanted to do some changes to the UI of the browser so the space used for the actual content of a webpage is maximized and it is not displaying active UI elements that I do not use.
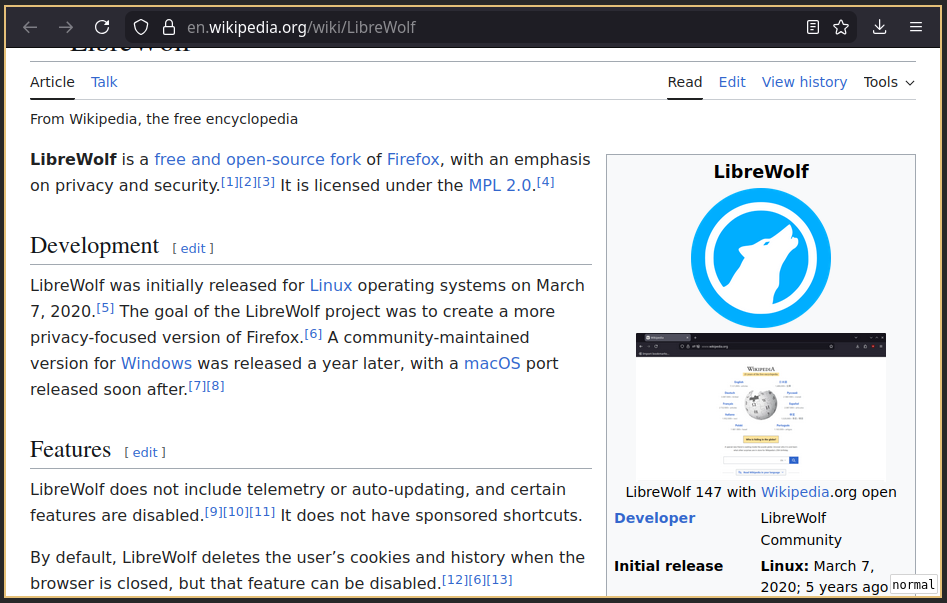
The result is a quite clean web browsing experience as can be seen on the screenshot above. It works nicely on large screens as well as smaller tiled areas as can be seen in the example.
How to set this up
I’m describing how to install the setup here so I can remember when moving to a different installation. First you have to install the LibreWolf browser on your linux machine. The complete setup should in my eyes also work on MacOS or even Windows machines even though I have never tested it myself. The LibreWolf website describes the installation for the various operating systems.
After that you have to install the Tridactyl browser extension through the extension management in about:addons. Open that page in your browser, search for the plugin and apply it.
Once that is done I have opted for the default dark theme. This can be selected in about:preferences.
Next I wanted to hide the huge tab bar on the top of the browser. Tridactyle offers a tab list by pressing b, but I found that I do not use nearly as many open tabs at a time now that I use this extension3. This can be achieved by using a userChrome.css file4.
That file has to go into your browser profile directory which is located in your home config directory.
/* asciijungles's userChrome.css
* write to ~/.config/librewolf/librewolf/{yourProfile}/chrome/userChrome.css
*/
/* hide header tab bar */
#TabsToolbar {
visibility: collapse !important;
}
/* hide huge sidebar header*/
#sidebar-header, #search-box {
display: none!important;
}
#sidebar-header {
display: none !important;
}
/* minimize sidebar splitter */
#sidebar-splitter {
background-color: black!important;
width: 1px!important;
border: 0px!important;
}After that you have to enable usage of the userChrome file in about:config. On that page you are able to set values for configuration properties. Serch for the following config and toggle its value to be true.
toolkit.legacyUserProfileCustomizations.stylesheets = trueThe changes apply after a restart of the program.
Last quick thing: I like to cycle through the open tabs with Ctrl + Tab. I use the setting “Activate Ctrl+Tab cycles through tabs in recently used order” that can be set in about:preferences. That way I can always jump back to the previous tab instead of tabbing through the whole list. Try it, it’s nice.
That is all you have to do to clone my setup. Enjoy.
What I wish for
I’m very happy with the setup as is at the moment. But there is one thing that I would really love to have. The browser supports multiple profiles with separate histories and shared sessions between tabs. In order to change profiles you have to start a different instance of the browser program. At work I have different profiles for different customers I work for and can be logged in to several web applications using OpenID Connect. I have to run two browsers and switch between them on different workspaces. It works but, I think it would be awesome to be able to use different profiles per tab in the same session. I imagine to be able to have a keybinding “open in profile 2” that opens in a profile other than my default.
What do you think? How are you using your browser? I’d love to hear about it. Please get in touch with me on the fediverse.
Footnotes
Servo is an independent browser engine implementation written in Rust: https://servo.org/.↩︎
Even though there has been a significant improvements in the recent years, the Servo Browser Engine is not quite usable as a daily driver.↩︎
Others seem to have experienced the same. For example KW Stannard has blogged about this on dev.to.↩︎
You can actually change a lot of the firefox UI with a local css file which is pretty awesome! check out: https://www.userchrome.org/what-is-userchrome-css.html↩︎